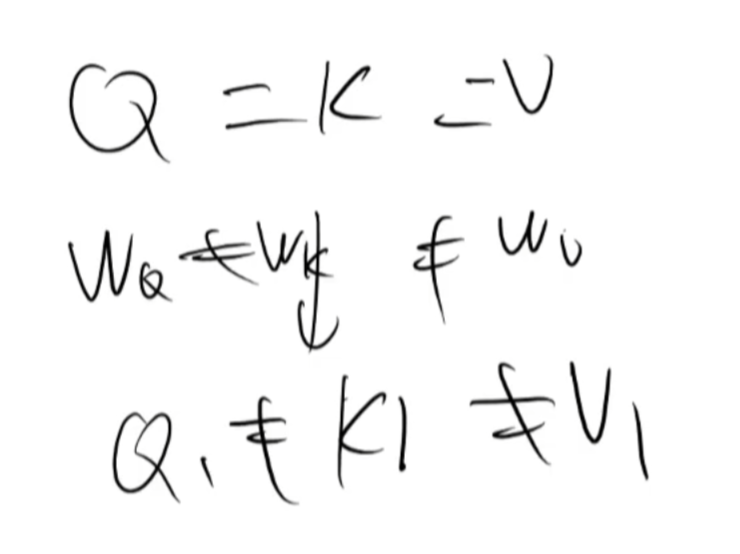null
1、说一下transformer
有一个多抽头self-attention和一个FFN前馈网络组成,attention获取上下文信息,ffn用于存储知识;
利用resnet模式,解决了快速收敛和梯度消失问题;
有encoder和decoder,encoder可以看到全部信息,decoder可以看到部分信息;
2、transformer加速:kv-cache
3、为什么是ln不是bn
bn需要序列长度一样,bn不适合nlp
4、bn和ln的区别
对数据进行标准化,将输入数据归一化到正态分布,加速收敛,提高训练稳定性;
bn是。。。
bn缺点:无法处理变长数据、语义数据
ln:

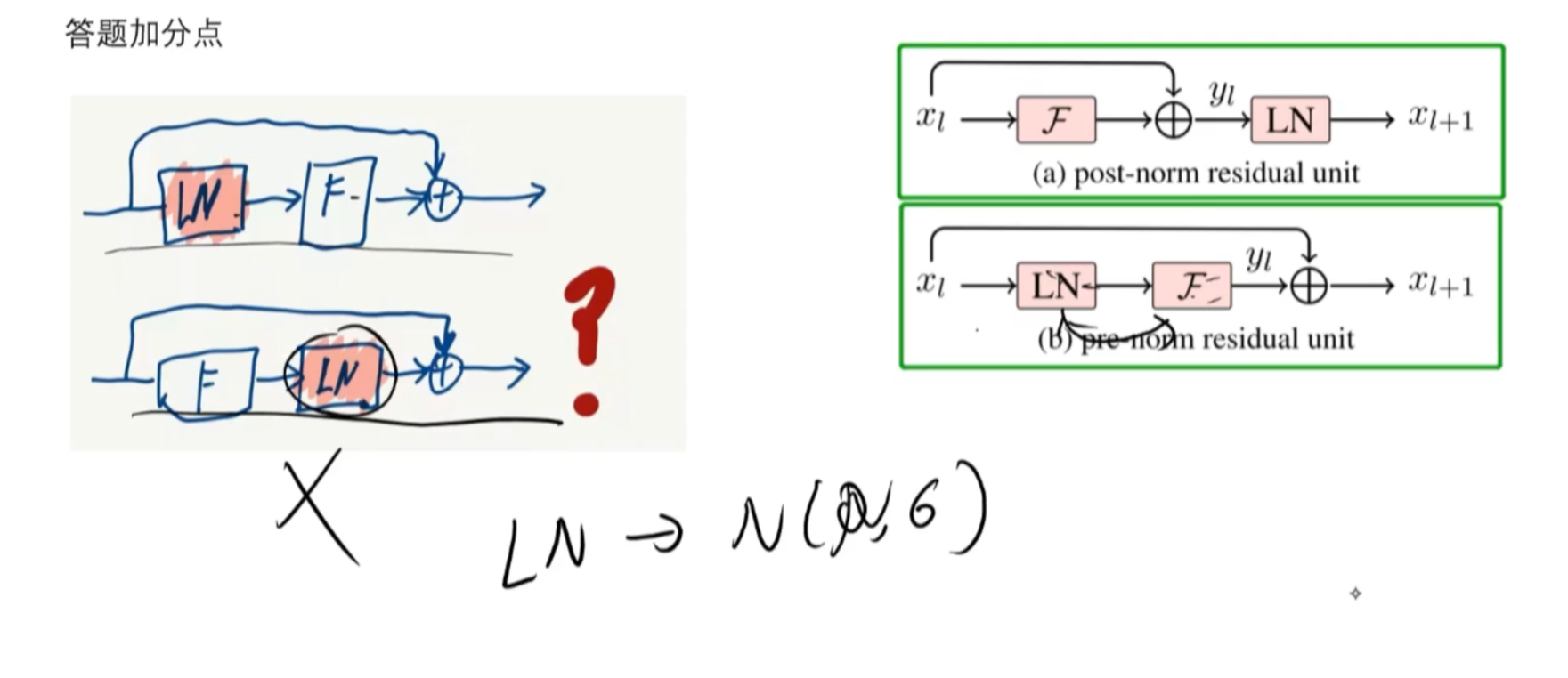
5、prenorm和postnorm
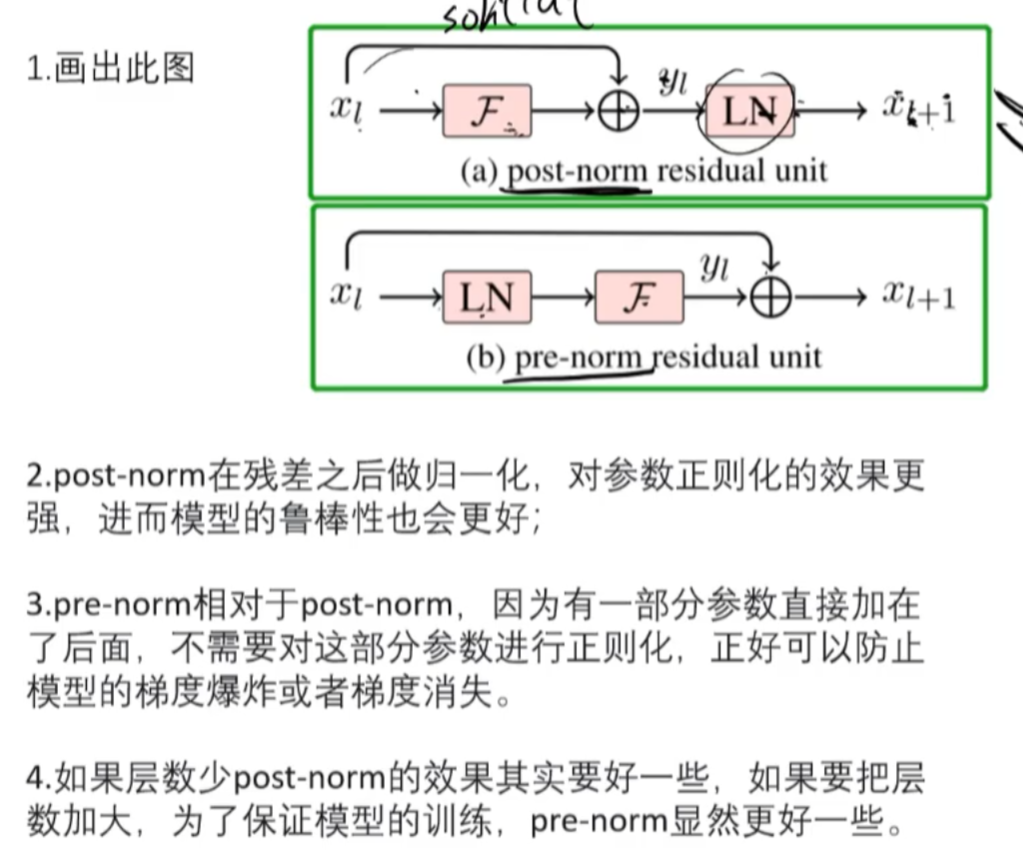
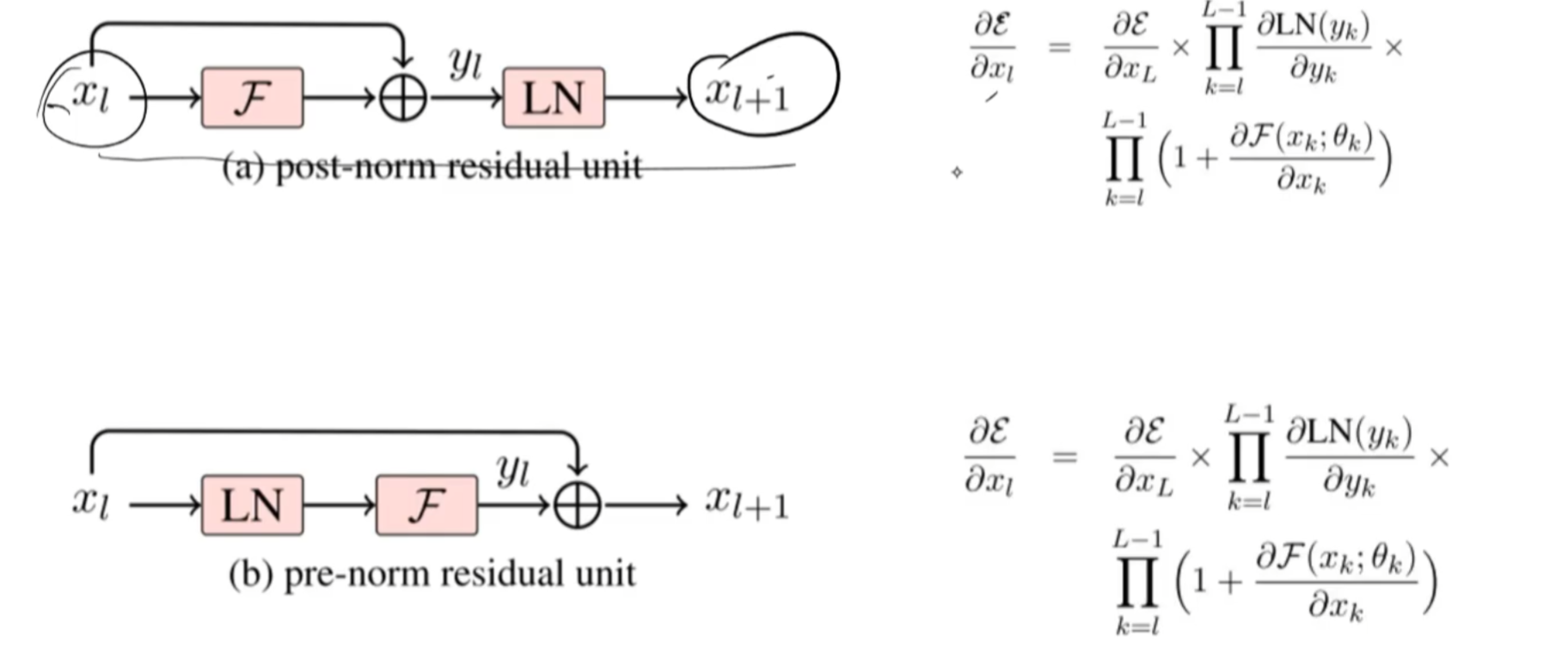
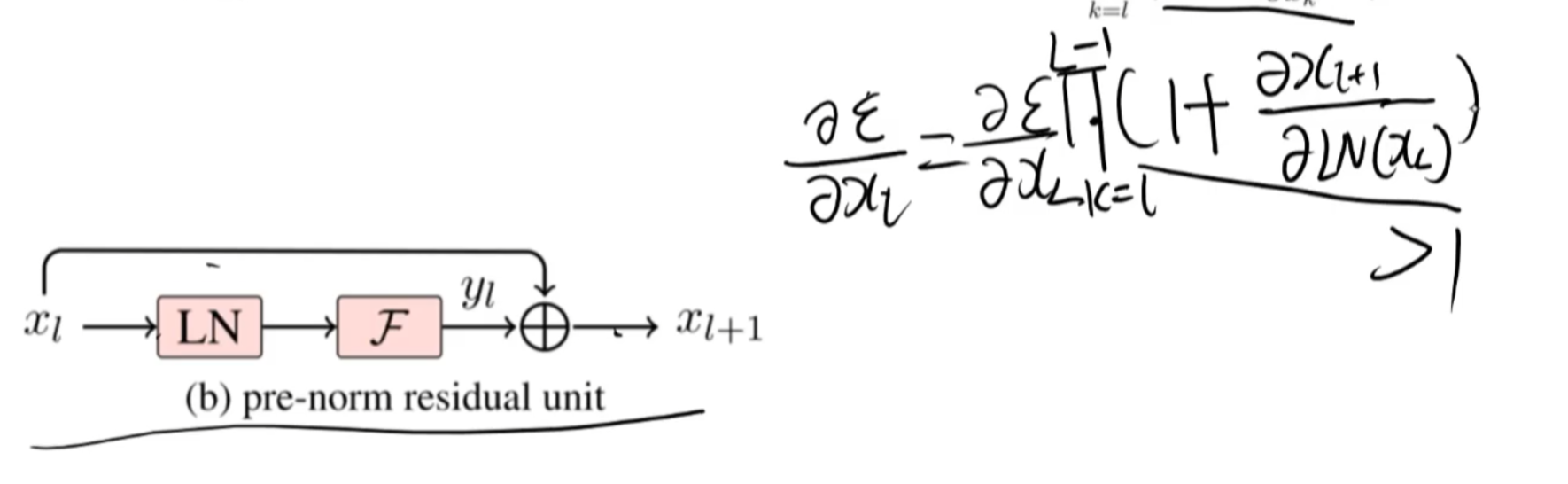
LN把分布正态化,数值小
6、为什么self-attention的qkv用三个不同矩阵